Class Documentation and C++ Reference¶
This section provides a breakdown of the cpp classes and what each of their functions provide. It is partially generated and augomented from the Doxygen autodoc content. You can also go directly to the raw doxygen docs.
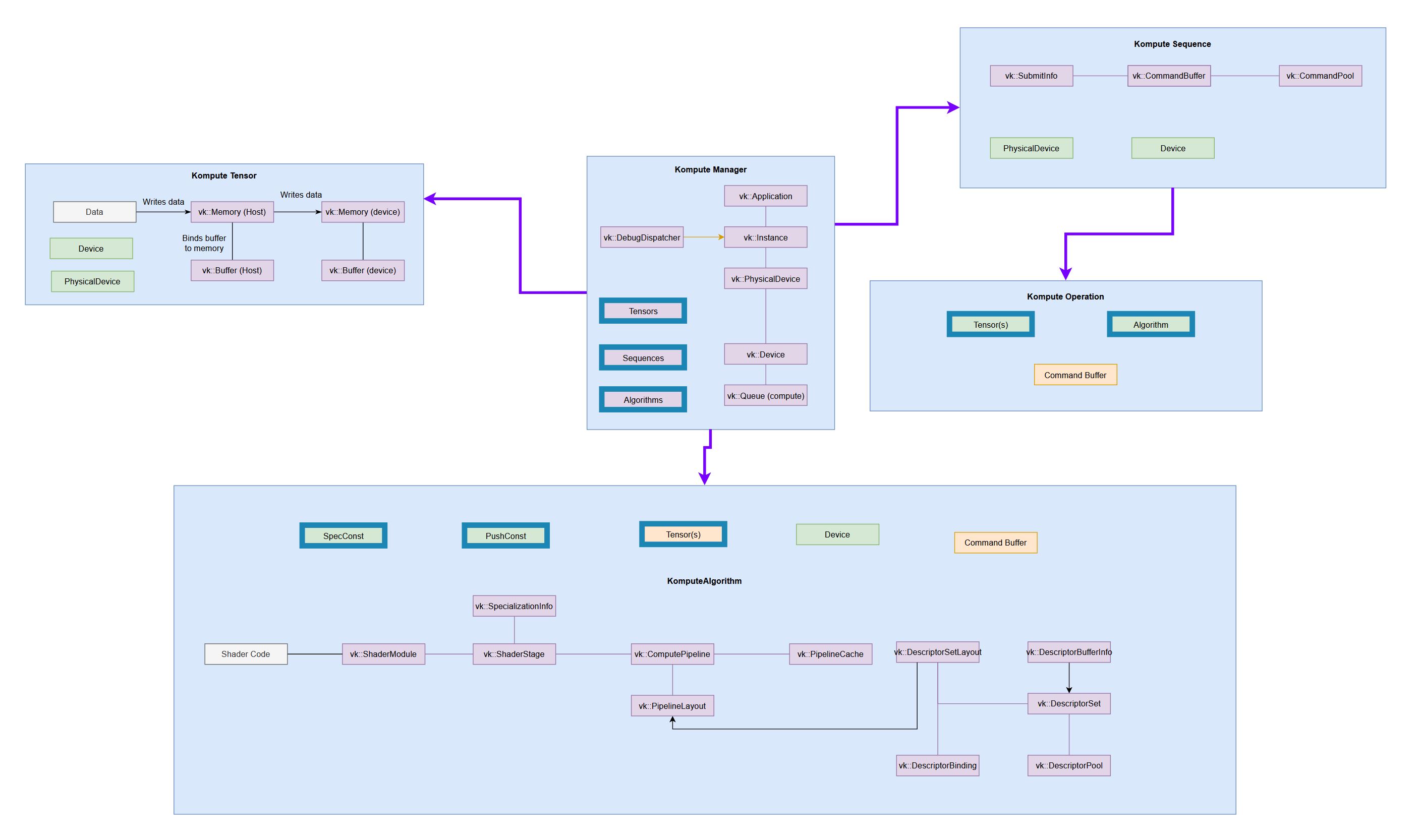
Below is a diagram that provides insights on the relationship between Kompute objects and Vulkan SDK resources, which primarily encompass ownership of either CPU and/or GPU memory.
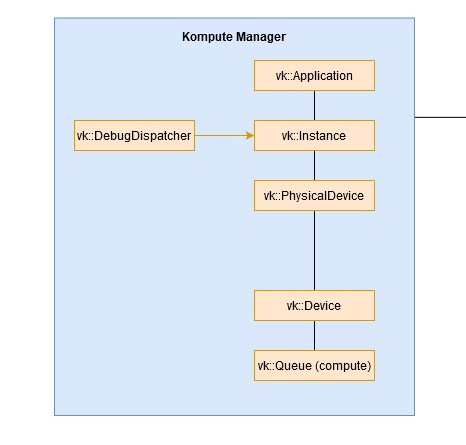
Manager¶
The Kompute Manager provides a high level interface to simplify interaction with underlying kp::Sequences of kp::Operations.
-
class
kp::Manager¶ Base orchestrator which creates and manages device and child components
Public Functions
-
Manager()¶ Base constructor and default used which creates the base resources including choosing the device 0 by default.
-
Manager(uint32_t physicalDeviceIndex, const std::vector<uint32_t> &familyQueueIndices = {}, const std::vector<std::string> &desiredExtensions = {})¶ Similar to base constructor but allows for further configuration to use when creating the Vulkan resources.
- Parameters
physicalDeviceIndex: The index of the physical device to usefamilyQueueIndices: (Optional) List of queue indices to add for explicit allocationdesiredExtensions: The desired extensions to load from physicalDevice
Manager constructor which allows your own vulkan application to integrate with the kompute use.
- Parameters
instance: Vulkan compute instance to base this applicationphysicalDevice: Vulkan physical device to use for applicationdevice: Vulkan logical device to use for all base resourcesphysicalDeviceIndex: Index for vulkan physical device used
-
~Manager()¶ Manager destructor which would ensure all owned resources are destroyed unless explicitly stated that resources should not be destroyed or freed.
-
std::shared_ptr<Sequence>
sequence(uint32_t queueIndex = 0, uint32_t totalTimestamps = 0)¶ Create a managed sequence that will be destroyed by this manager if it hasn’t been destroyed by its reference count going to zero.
- Return
Shared pointer with initialised sequence
- Parameters
queueIndex: The queue to use from the available queuesnrOfTimestamps: The maximum number of timestamps to allocate. If zero (default), disables latching of timestamps.
Create a managed tensor that will be destroyed by this manager if it hasn’t been destroyed by its reference count going to zero.
- Return
Shared pointer with initialised tensor
- Parameters
data: The data to initialize the tensor withtensorType: The type of tensor to initialize
Default non-template function that can be used to create algorithm objects which provides default types to the push and spec constants as floats.
- Return
Shared pointer with initialised algorithm
- Parameters
tensors: (optional) The tensors to initialise the algorithm withspirv: (optional) The SPIRV bytes for the algorithm to dispatchworkgroup: (optional) kp::Workgroup for algorithm to use, and defaults to (tensor[0].size(), 1, 1)specializationConstants: (optional) float vector to use for specialization constants, and defaults to an empty constantpushConstants: (optional) float vector to use for push constants, and defaults to an empty constant
Create a managed algorithm that will be destroyed by this manager if it hasn’t been destroyed by its reference count going to zero.
- Return
Shared pointer with initialised algorithm
- Parameters
tensors: (optional) The tensors to initialise the algorithm withspirv: (optional) The SPIRV bytes for the algorithm to dispatchworkgroup: (optional) kp::Workgroup for algorithm to use, and defaults to (tensor[0].size(), 1, 1)specializationConstants: (optional) templatable vector parameter to use for specialization constants, and defaults to an empty constantpushConstants: (optional) templatable vector parameter to use for push constants, and defaults to an empty constant
-
void
destroy()¶ Destroy the GPU resources and all managed resources by manager.
-
void
clear()¶ Run a pseudo-garbage collection to release all the managed resources that have been already freed due to these reaching to zero ref count.
-
vk::PhysicalDeviceProperties
getDeviceProperties() const¶ Information about the current device.
- Return
vk::PhysicalDeviceProperties containing information about the device
-
std::vector<vk::PhysicalDevice>
listDevices() const¶ List the devices available in the current vulkan instance.
- Return
vector of physical devices containing their respective properties
-
std::shared_ptr<vk::Instance>
getVkInstance() const¶ The current Vulkan instance.
- Return
a shared pointer to the current Vulkan instance held by this object
-
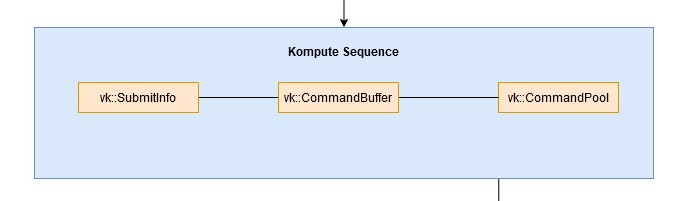
Sequence¶
The Kompute Sequence consists of batches of kp::Operations, which are executed on a respective GPU queue. The execution of sequences can be synchronous or asynchronous, and it can be coordinated through its respective vk::Fence.
-
class
kp::Sequence: public std::enable_shared_from_this<Sequence>¶ Container of operations that can be sent to GPU as batch
Public Functions
Main constructor for sequence which requires core vulkan components to generate all dependent resources.
- Parameters
physicalDevice: Vulkan physical devicedevice: Vulkan logical devicecomputeQueue: Vulkan compute queuequeueIndex: Vulkan compute queue index in devicetotalTimestamps: Maximum number of timestamps to allocate
-
~Sequence()¶ Destructor for sequence which is responsible for cleaning all subsequent owned operations.
Record function for operation to be added to the GPU queue in batch. This template requires classes to be derived from the OpBase class. This function also requires the Sequence to be recording, otherwise it will not be able to add the operation.
- Return
shared_ptr<Sequence> of the Sequence class itself
- Parameters
op: Object derived from kp::BaseOp that will be recoreded by the sequence which will be used when the operation is evaluated.
Record function for operation to be added to the GPU queue in batch. This template requires classes to be derived from the OpBase class. This function also requires the Sequence to be recording, otherwise it will not be able to add the operation.
- Return
shared_ptr<Sequence> of the Sequence class itself
- Parameters
tensors: Vector of tensors to use for the operationTArgs: Template parameters that are used to initialise operation which allows for extensible configurations on initialisation.
Record function for operation to be added to the GPU queue in batch. This template requires classes to be derived from the OpBase class. This function also requires the Sequence to be recording, otherwise it will not be able to add the operation.
-
std::shared_ptr<Sequence>
eval()¶ Eval sends all the recorded and stored operations in the vector of operations into the gpu as a submit job synchronously (with a barrier).
- Return
shared_ptr<Sequence> of the Sequence class itself
Resets all the recorded and stored operations, records the operation provided and submits into the gpu as a submit job synchronously (with a barrier).
- Return
shared_ptr<Sequence> of the Sequence class itself
Eval sends all the recorded and stored operations in the vector of operations into the gpu as a submit job with a barrier.
- Return
shared_ptr<Sequence> of the Sequence class itself
- Parameters
tensors: Vector of tensors to use for the operationTArgs: Template parameters that are used to initialise operation which allows for extensible configurations on initialisation.
Eval sends all the recorded and stored operations in the vector of operations into the gpu as a submit job with a barrier.
-
std::shared_ptr<Sequence>
evalAsync()¶ Eval Async sends all the recorded and stored operations in the vector of operations into the gpu as a submit job without a barrier. EvalAwait() must ALWAYS be called after to ensure the sequence is terminated correctly.
- Return
Boolean stating whether execution was successful.
Clears currnet operations to record provided one in the vector of operations into the gpu as a submit job without a barrier. EvalAwait() must ALWAYS be called after to ensure the sequence is terminated correctly.
- Return
Boolean stating whether execution was successful.
Eval sends all the recorded and stored operations in the vector of operations into the gpu as a submit job with a barrier.
- Return
shared_ptr<Sequence> of the Sequence class itself
- Parameters
tensors: Vector of tensors to use for the operationTArgs: Template parameters that are used to initialise operation which allows for extensible configurations on initialisation.
Eval sends all the recorded and stored operations in the vector of operations into the gpu as a submit job with a barrier.
-
std::shared_ptr<Sequence>
evalAwait(uint64_t waitFor = UINT64_MAX)¶ Eval Await waits for the fence to finish processing and then once it finishes, it runs the postEval of all operations.
- Return
shared_ptr<Sequence> of the Sequence class itself
- Parameters
waitFor: Number of milliseconds to wait before timing out.
-
void
clear()¶ Clear function clears all operations currently recorded and starts recording again.
-
std::vector<std::uint64_t>
getTimestamps()¶ Return the timestamps that were latched at the beginning and after each operation during the last eval() call.
-
void
begin()¶ Begins recording commands for commands to be submitted into the command buffer.
-
void
end()¶ Ends the recording and stops recording commands when the record command is sent.
-
bool
isRecording() const¶ Returns true if the sequence is currently in recording activated.
- Return
Boolean stating if recording ongoing.
-
bool
isInit() const¶ Returns true if the sequence has been initialised, and it’s based on the GPU resources being referenced.
- Return
Boolean stating if is initialized
-
void
rerecord()¶ Clears command buffer and triggers re-record of all the current operations saved, which is useful if the underlying kp::Tensors or kp::Algorithms are modified and need to be re-recorded.
-
bool
isRunning() const¶ Returns true if the sequence is currently running - mostly used for async workloads.
- Return
Boolean stating if currently running.
-
void
destroy()¶ Destroys and frees the GPU resources which include the buffer and memory and sets the sequence as init=False.
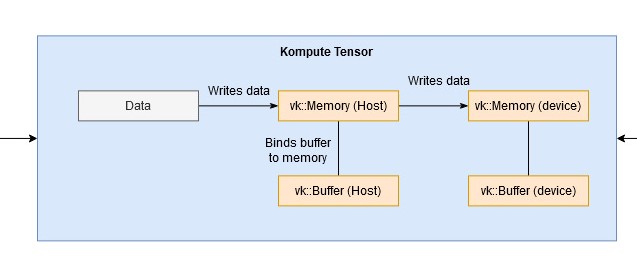
Tensor¶
The kp::Tensor is the atomic unit in Kompute, and it is used primarily for handling Host and GPU Device data.
-
class
kp::Tensor¶ Structured data used in GPU operations.
Tensors are the base building block in Kompute to perform operations across GPUs. Each tensor would have a respective Vulkan memory and buffer, which would be used to store their respective data. The tensors can be used for GPU data storage or transfer.
Subclassed by kp::TensorT< T >
Public Types
-
enum
TensorTypes¶ Type for tensors created: Device allows memory to be transferred from staging buffers. Staging are host memory visible. Storage are device visible but are not set up to transfer or receive data (only for shader storage).
Values:
-
enumerator
eDevice= 0¶ Type is device memory, source and destination.
-
enumerator
eHost= 1¶ Type is host memory, source and destination.
-
enumerator
eStorage= 2¶ Type is Device memory (only)
-
enumerator
Public Functions
Constructor with data provided which would be used to create the respective vulkan buffer and memory.
- Parameters
physicalDevice: The physical device to use to fetch propertiesdevice: The device to use to create the buffer and memory fromdata: Non-zero-sized vector of data that will be used by the tensortensorTypes: Type for the tensor which is of type TensorTypes
-
~Tensor()¶ Destructor which is in charge of freeing vulkan resources unless they have been provided externally.
-
void
rebuild(void *data, uint32_t elementTotalCount, uint32_t elementMemorySize)¶ Function to trigger reinitialisation of the tensor buffer and memory with new data as well as new potential device type.
- Parameters
data: Vector of data to use to initialise vector fromtensorType: The type to use for the tensor
-
void
destroy()¶ Destroys and frees the GPU resources which include the buffer and memory.
-
bool
isInit()¶ Check whether tensor is initialized based on the created gpu resources.
- Return
Boolean stating whether tensor is initialized
-
TensorTypes
tensorType()¶ Retrieve the tensor type of the Tensor
- Return
Tensor type of tensor
Records a copy from the memory of the tensor provided to the current thensor. This is intended to pass memory into a processing, to perform a staging buffer transfer, or to gather output (between others).
- Parameters
commandBuffer: Vulkan Command Buffer to record the commands intocopyFromTensor: Tensor to copy the data from
-
void
recordCopyFromStagingToDevice(const vk::CommandBuffer &commandBuffer)¶ Records a copy from the internal staging memory to the device memory using an optional barrier to wait for the operation. This function would only be relevant for kp::Tensors of type eDevice.
- Parameters
commandBuffer: Vulkan Command Buffer to record the commands into
-
void
recordCopyFromDeviceToStaging(const vk::CommandBuffer &commandBuffer)¶ Records a copy from the internal device memory to the staging memory using an optional barrier to wait for the operation. This function would only be relevant for kp::Tensors of type eDevice.
- Parameters
commandBuffer: Vulkan Command Buffer to record the commands into
-
void
recordPrimaryBufferMemoryBarrier(const vk::CommandBuffer &commandBuffer, vk::AccessFlagBits srcAccessMask, vk::AccessFlagBits dstAccessMask, vk::PipelineStageFlagBits srcStageMask, vk::PipelineStageFlagBits dstStageMask)¶ Records the buffer memory barrier into the primary buffer and command buffer which ensures that relevant data transfers are carried out correctly.
- Parameters
commandBuffer: Vulkan Command Buffer to record the commands intosrcAccessMask: Access flags for source access maskdstAccessMask: Access flags for destination access maskscrStageMask: Pipeline stage flags for source stage maskdstStageMask: Pipeline stage flags for destination stage mask
-
void
recordStagingBufferMemoryBarrier(const vk::CommandBuffer &commandBuffer, vk::AccessFlagBits srcAccessMask, vk::AccessFlagBits dstAccessMask, vk::PipelineStageFlagBits srcStageMask, vk::PipelineStageFlagBits dstStageMask)¶ Records the buffer memory barrier into the staging buffer and command buffer which ensures that relevant data transfers are carried out correctly.
- Parameters
commandBuffer: Vulkan Command Buffer to record the commands intosrcAccessMask: Access flags for source access maskdstAccessMask: Access flags for destination access maskscrStageMask: Pipeline stage flags for source stage maskdstStageMask: Pipeline stage flags for destination stage mask
-
vk::DescriptorBufferInfo
constructDescriptorBufferInfo()¶ Constructs a vulkan descriptor buffer info which can be used to specify and reference the underlying buffer component of the tensor without exposing it.
- Return
Descriptor buffer info with own buffer
-
uint32_t
size()¶ Returns the size/magnitude of the Tensor, which will be the total number of elements across all dimensions
- Return
Unsigned integer representing the total number of elements
-
uint32_t
dataTypeMemorySize()¶ Returns the total size of a single element of the respective data type that this tensor holds.
- Return
Unsigned integer representing the memory of a single element of the respective data type.
-
uint32_t
memorySize()¶ Returns the total memory size of the data contained by the Tensor object which would equate to (this->size() * this->dataTypeMemorySize())
- Return
Unsigned integer representing the memory of a single element of the respective data type.
-
TensorDataTypes
dataType()¶ Retrieve the data type of the tensor (host, device, storage)
- Return
Data type of tensor of type kp::Tensor::TensorDataTypes
-
void *
rawData()¶ Retrieve the raw data via the pointer to the memory that contains the raw memory of this current tensor. This tensor gets changed to a nullptr when the Tensor is removed.
- Return
Pointer to raw memory containing raw bytes data of Tensor.
-
void
setRawData(const void *data)¶ Sets / resets the data of the tensor which is directly done on the GPU host visible memory available by the tensor.
-
enum
Algorithm¶
The kp::Algorithm consists primarily of the components required for shader code execution, including the relevant vk::DescriptorSet relatedresources as well as vk::Pipeline and all the relevant Vulkan SDK resources as outlined in the architectural diagram.
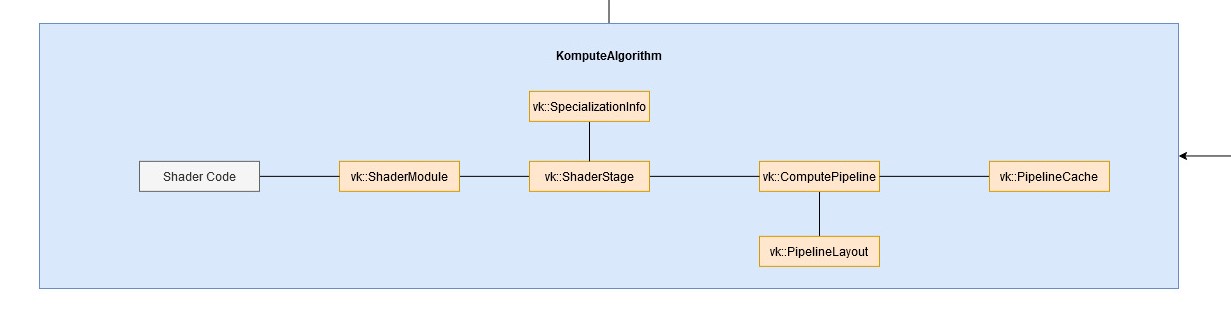
-
class
kp::Algorithm¶ Abstraction for compute shaders that are run on top of tensors grouped via ParameterGroups (which group descriptorsets)
Public Functions
Main constructor for algorithm with configuration parameters to create the underlying resources.
- Parameters
device: The Vulkan device to use for creating resourcestensors: (optional) The tensors to use to create the descriptor resourcesspirv: (optional) The spirv code to use to create the algorithmworkgroup: (optional) The kp::Workgroup to use for the dispatch which defaults to kp::Workgroup(tensor[0].size(), 1, 1) if not set.specializationConstants: (optional) The templatable param is to be used to initialize the specialization constants which cannot be changed once set.pushConstants: (optional) This templatable param is to be used when initializing the pipeline, which set the size of the push constantsthese can be modified but all new values must have the same data type and length as otherwise it will result in errors.
Rebuild function to reconstruct algorithm with configuration parameters to create the underlying resources.
- Parameters
tensors: The tensors to use to create the descriptor resourcesspirv: The spirv code to use to create the algorithmworkgroup: (optional) The kp::Workgroup to use for the dispatch which defaults to kp::Workgroup(tensor[0].size(), 1, 1) if not set.specializationConstants: (optional) The std::vector<float> to use to initialize the specialization constants which cannot be changed once set.pushConstants: (optional) The std::vector<float> to use when initializing the pipeline, which set the size of the push constants - these can be modified but all new values must have the same vector size as this initial value.
-
~Algorithm()¶ Destructor for Algorithm which is responsible for freeing and desroying respective pipelines and owned parameter groups.
-
void
recordDispatch(const vk::CommandBuffer &commandBuffer)¶ Records the dispatch function with the provided template parameters or alternatively using the size of the tensor by default.
- Parameters
commandBuffer: Command buffer to record the algorithm resources to
-
void
recordBindCore(const vk::CommandBuffer &commandBuffer)¶ Records command that binds the “core” algorithm components which consist of binding the pipeline and binding the descriptorsets.
- Parameters
commandBuffer: Command buffer to record the algorithm resources to
-
void
recordBindPush(const vk::CommandBuffer &commandBuffer)¶ Records command that binds the push constants to the command buffer provided
it is required that the pushConstants provided are of the same size as the ones provided during initialization.
- Parameters
commandBuffer: Command buffer to record the algorithm resources to
-
bool
isInit()¶ function that checks all the gpu resource components to verify if these have been created and returns true if all are valid.
- Return
returns true if the algorithm is currently initialized.
-
void
setWorkgroup(const Workgroup &workgroup, uint32_t minSize = 1)¶ Sets the work group to use in the recordDispatch
- Parameters
workgroup: The kp::Workgroup value to use to update the algorithm. It must have a value greater than 1 on the x value (index 1) otherwise it will be initialized on the size of the first tensor (ie. this->mTensor[0]->size())
-
template<typename
T>
voidsetPushConstants(const std::vector<T> &pushConstants)¶ Sets the push constants to the new value provided to use in the next bindPush()
- Parameters
pushConstants: The templatable vector is to be used to set the push constants to use in the next bindPush(…) calls. The constants provided must be of the same size as the ones created during initialization.
-
void
setPushConstants(void *data, uint32_t size, uint32_t memorySize)¶ Sets the push constants to the new value provided to use in the next bindPush() with the raw memory block location and memory size to be used.
- Parameters
data: The raw data point to copy the data from, without modifying the pointer.size: The number of data elements provided in the datamemorySize: The memory size of each of the data elements in bytes.
-
const Workgroup &
getWorkgroup()¶ Gets the current workgroup from the algorithm.
- Parameters
The: kp::Constant to use to set the push constants to use in the next bindPush(…) calls. The constants provided must be of the same size as the ones created during initialization.
-
template<typename
T>
const std::vector<T>getSpecializationConstants()¶ Gets the specialization constants of the current algorithm.
- Return
The std::vector<float> currently set for specialization constants
OpBase¶
The kp::OpBase provides a top level class for an operation in Kompute, which is the step that is executed on a GPU submission. The Kompute operations can consist of one or more kp::Tensor.
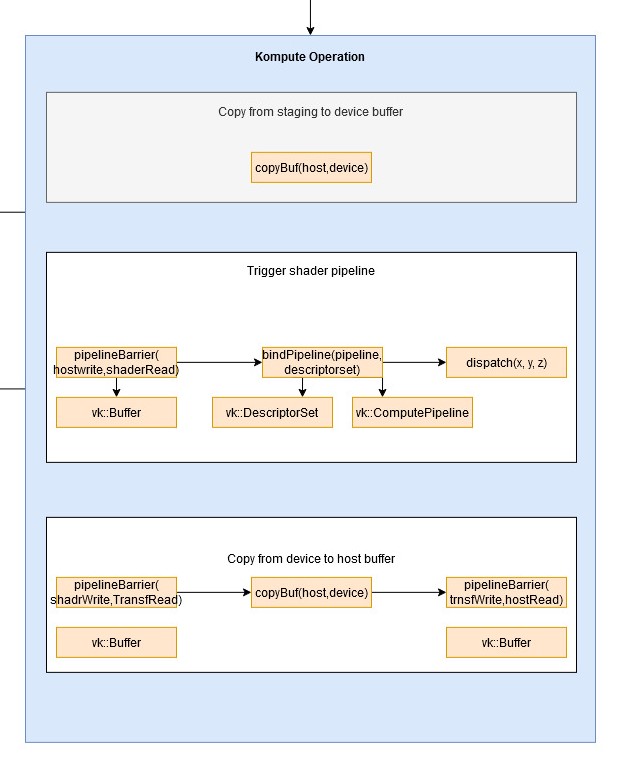
-
class
kp::OpBase¶ Base Operation which provides the high level interface that Kompute operations implement in order to perform a set of actions in the GPU.
Operations can perform actions on tensors, and optionally can also own an Algorithm with respective parameters. kp::Operations with kp::Algorithms would inherit from kp::OpBaseAlgo.
Subclassed by kp::OpAlgoDispatch, kp::OpMemoryBarrier, kp::OpTensorCopy, kp::OpTensorSyncDevice, kp::OpTensorSyncLocal
Public Functions
-
~OpBase()¶ Default destructor for OpBase class. This OpBase destructor class should always be called to destroy and free owned resources unless it is intended to destroy the resources in the parent class.
-
void
record(const vk::CommandBuffer &commandBuffer) = 0¶ The record function is intended to only send a record command or run commands that are expected to record operations that are to be submitted as a batch into the GPU.
- Parameters
commandBuffer: The command buffer to record the command into.
-
void
preEval(const vk::CommandBuffer &commandBuffer) = 0¶ Pre eval is called before the Sequence has called eval and submitted the commands to the GPU for processing, and can be used to perform any per-eval setup steps required as the computation iteration begins. It’s worth noting that there are situations where eval can be called multiple times, so the resources that are created should be idempotent in case it’s called multiple times in a row.
- Parameters
commandBuffer: The command buffer to record the command into.
-
void
postEval(const vk::CommandBuffer &commandBuffer) = 0¶ Post eval is called after the Sequence has called eval and submitted the commands to the GPU for processing, and can be used to perform any tear-down steps required as the computation iteration finishes. It’s worth noting that there are situations where eval can be called multiple times, so the resources that are destroyed should not require a re-init unless explicitly provided by the user.
- Parameters
commandBuffer: The command buffer to record the command into.
-
OpAlgoDispatch¶
The vk::OpAlgoDispatch extends the vk::OpBase class, and provides the base for shader-based operations. Besides of consisting of one or more vk::Tensor as per the vk::OpBase, it also contains a unique vk::Algorithm.
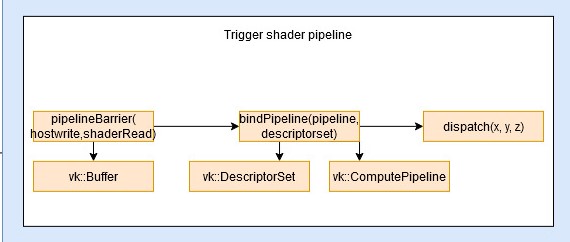
-
class
kp::OpAlgoDispatch: public kp::OpBase¶ Operation that provides a general abstraction that simplifies the use of algorithm and parameter components which can be used with shaders. By default it enables the user to provide a dynamic number of tensors which are then passed as inputs.
Subclassed by kp::OpMult
Public Functions
Constructor that stores the algorithm to use as well as the relevant push constants to override when recording.
- Parameters
algorithm: The algorithm object to use for dispatchpushConstants: The push constants to use for override
-
~OpAlgoDispatch() override¶ Default destructor, which is in charge of destroying the algorithm components but does not destroy the underlying tensors
-
void
record(const vk::CommandBuffer &commandBuffer) override¶ This records the commands that are to be sent to the GPU. This includes the barriers that ensure the memory has been copied before going in and out of the shader, as well as the dispatch operation that sends the shader processing to the gpu. This function also records the GPU memory copy of the output data for the staging buffer so it can be read by the host.
- Parameters
commandBuffer: The command buffer to record the command into.
-
void
preEval(const vk::CommandBuffer &commandBuffer) override¶ Does not perform any preEval commands.
- Parameters
commandBuffer: The command buffer to record the command into.
-
void
postEval(const vk::CommandBuffer &commandBuffer) override¶ Does not perform any postEval commands.
- Parameters
commandBuffer: The command buffer to record the command into.
OpMult¶
The kp::OpMult operation is a sample implementation of the kp::OpAlgoBase class. This class shows how it is possible to create a custom vk::OpAlgoBase that can compile as part of the binary. The kp::OpMult operation uses the shader-to-cpp-header-file script to convert the script into cpp header files.
-
class
kp::OpMult: public kp::OpAlgoDispatch¶ Operation that performs multiplication on two tensors and outpus on third tensor.
Public Functions
Default constructor with parameters that provides the bare minimum requirements for the operations to be able to create and manage their sub-components.
- Parameters
tensors: Tensors that are to be used in this operationalgorithm: An algorithm that will be overridden with the OpMult shader data and the tensors provided which are expected to be 3
-
~OpMult() override¶ Default destructor, which is in charge of destroying the algorithm components but does not destroy the underlying tensors
OpTensorCopy¶
The kp::OpTensorCopy is a tensor only operation that copies the GPU memory buffer data from one kp::Tensor to one or more subsequent tensors.
-
class
kp::OpTensorCopy: public kp::OpBase¶ Operation that copies the data from the first tensor to the rest of the tensors provided, using a record command for all the vectors. This operation does not own/manage the memory of the tensors passed to it. The operation must only receive tensors of type
Public Functions
Default constructor with parameters that provides the core vulkan resources and the tensors that will be used in the operation.
- Parameters
tensors: Tensors that will be used to create in operation.
-
~OpTensorCopy() override¶ Default destructor. This class does not manage memory so it won’t be expecting the parent to perform a release.
-
void
record(const vk::CommandBuffer &commandBuffer) override¶ Records the copy commands from the first tensor into all the other tensors provided. Also optionally records a barrier.
- Parameters
commandBuffer: The command buffer to record the command into.
-
void
preEval(const vk::CommandBuffer &commandBuffer) override¶ Does not perform any preEval commands.
- Parameters
commandBuffer: The command buffer to record the command into.
-
void
postEval(const vk::CommandBuffer &commandBuffer) override¶ Copies the local vectors for all the tensors to sync the data with the gpu.
- Parameters
commandBuffer: The command buffer to record the command into.
OpTensorSyncLocal¶
The kp::OpTensorSyncLocal is a tensor only operation that maps the data from the GPU device memory into the local host vector.
-
class
kp::OpTensorSyncLocal: public kp::OpBase¶ Operation that syncs tensor’s local memory by mapping device data into the local CPU memory. For TensorTypes::eDevice it will use a record operation for the memory to be syncd into GPU memory which means that the operation will be done in sync with GPU commands. For TensorTypes::eHost it will only map the data into host memory which will happen during preEval before the recorded commands are dispatched.
Public Functions
Default constructor with parameters that provides the core vulkan resources and the tensors that will be used in the operation. The tensors provided cannot be of type TensorTypes::eStorage.
- Parameters
tensors: Tensors that will be used to create in operation.
-
~OpTensorSyncLocal() override¶ Default destructor. This class does not manage memory so it won’t be expecting the parent to perform a release.
-
void
record(const vk::CommandBuffer &commandBuffer) override¶ For device tensors, it records the copy command for the tensor to copy the data from its device to staging memory.
- Parameters
commandBuffer: The command buffer to record the command into.
-
void
preEval(const vk::CommandBuffer &commandBuffer) override¶ Does not perform any preEval commands.
- Parameters
commandBuffer: The command buffer to record the command into.
-
void
postEval(const vk::CommandBuffer &commandBuffer) override¶ For host tensors it performs the map command from the host memory into local memory.
- Parameters
commandBuffer: The command buffer to record the command into.
OpTensorSyncDevice¶
The kp::OpTensorSyncDevice is a tensor only operation that maps the data from the local host vector into the GPU device memory.
-
class
kp::OpTensorSyncDevice: public kp::OpBase¶ Operation that syncs tensor’s device by mapping local data into the device memory. For TensorTypes::eDevice it will use a record operation for the memory to be syncd into GPU memory which means that the operation will be done in sync with GPU commands. For TensorTypes::eHost it will only map the data into host memory which will happen during preEval before the recorded commands are dispatched.
Public Functions
Default constructor with parameters that provides the core vulkan resources and the tensors that will be used in the operation. The tensos provided cannot be of type TensorTypes::eStorage.
- Parameters
tensors: Tensors that will be used to create in operation.
-
~OpTensorSyncDevice() override¶ Default destructor. This class does not manage memory so it won’t be expecting the parent to perform a release.
-
void
record(const vk::CommandBuffer &commandBuffer) override¶ For device tensors, it records the copy command for the tensor to copy the data from its staging to device memory.
- Parameters
commandBuffer: The command buffer to record the command into.
-
void
preEval(const vk::CommandBuffer &commandBuffer) override¶ Does not perform any preEval commands.
- Parameters
commandBuffer: The command buffer to record the command into.
-
void
postEval(const vk::CommandBuffer &commandBuffer) override¶ Does not perform any postEval commands.
- Parameters
commandBuffer: The command buffer to record the command into.
OpMemoryBarrier¶
The kp::OpMemoryBarrier is a tensor only operation which adds memory barriers to the tensors provided with the access and stage masks provided.
-
class
kp::OpTensorSyncDevice: public kp::OpBase Operation that syncs tensor’s device by mapping local data into the device memory. For TensorTypes::eDevice it will use a record operation for the memory to be syncd into GPU memory which means that the operation will be done in sync with GPU commands. For TensorTypes::eHost it will only map the data into host memory which will happen during preEval before the recorded commands are dispatched.
Public Functions
-
OpTensorSyncDevice(const std::vector<std::shared_ptr<Tensor>> &tensors) Default constructor with parameters that provides the core vulkan resources and the tensors that will be used in the operation. The tensos provided cannot be of type TensorTypes::eStorage.
- Parameters
tensors: Tensors that will be used to create in operation.
-
~OpTensorSyncDevice() override Default destructor. This class does not manage memory so it won’t be expecting the parent to perform a release.
-
void
record(const vk::CommandBuffer &commandBuffer) override For device tensors, it records the copy command for the tensor to copy the data from its staging to device memory.
- Parameters
commandBuffer: The command buffer to record the command into.
-
void
preEval(const vk::CommandBuffer &commandBuffer) override Does not perform any preEval commands.
- Parameters
commandBuffer: The command buffer to record the command into.
-
void
postEval(const vk::CommandBuffer &commandBuffer) override Does not perform any postEval commands.
- Parameters
commandBuffer: The command buffer to record the command into.
-